| Home | Libraries | People | FAQ | More |


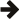
#include <boost/cgi.hpp> using namespace boost::cgi; int main() { request req; response resp; resp<< "Hello there, Universe. " << "-- " << req.get["name"]; return commit(req, resp); // write the response }
An example request:
GET example.com/program_name?name=Mr.+Allison HTTP/1.0
Output (as viewed in a web browser):
Hello there, Universe. -- Mr. Allison
This CGI library is a reasonably high-level library for creating CGI or FastCGI
programs and its scope is intentionally limited to the ''controller'' portion
of the Model-View-Controller idiom. If you want access to XML / HTML templates,
you should consider taking a look at cTemplate
or the Karma part of Boost.Spirit.
A very lightweight wrapper over cTemplate is provided with the library in the
form of the stencil
class, which you may find useful.
The library provides abstractions which hide details of the varying specifications of CGI and FastCGI. The main abstractions are, briefly:
|
Concept |
Purpose |
|---|---|
|
|
Access to all request data is done through a |
|
|
For those of you familiar with Boost.Asio, this is very similar to
the |
|
|
CGI applications handle one request per process, a limitation which
doesn't apply to SCGI and FastCGI applications. Using a |
|
|
Using the |
|
|
Each request has an associated Client, which may represent a connection
to the HTTP server associated with the current request. It is used
when writing replies to requests. Note: it is possible to avoid exposure
to it entirely if you use the |
[1] Taken from simultaneous suggestions by Phil Endecott and Chris Kohlhoff | |
In a nutshell, CGI is the simple and 'original' way of communicating with web servers. I'll assume you know what it is: one request per process and communication using standard input/output. A nice and simple way of making dynamic web pages.
![[Tip]](../../doc/html/images/tip.png) |
Tip |
|---|---|
If you're new to CGI, have a look at the original "spec": http://hoohoo.ncsa.uiuc.edu/cgi/ or on Wikipedia. |
FastCGI was developed as a means of allowing much more scalable CGI-like programs to be written. In fact, the FastCGI specification implies extreme efficiency and scalability were key motivations for the protocol. In FastCGI, communication with the server works over sockets or pipes using a binary-encoded protocol. Each process and each connection can be used for handling multiple requests, simultaneously if necessary. In theory this means you could have a single monolithic process behind your HTTP server handling all incoming requests concurrently.
![[Note]](../../doc/html/images/note.png) |
Note |
|---|---|
Some initial benchmarks show that the simplest FastCGI programs are 3-5x faster than their CGI counterparts. When database connections, HTML templates or any other expensive state is required the gap will be more significant. |
Having persistent processes is very handy: this feature alone removes many of the limitations of traditional CGI programming.
Instead of CGI 'scripts', you can suddenly have FastCGI daemons, which aren't
so different to desktop applications! Your web applications can handle an arbitrary
number of requests with each invocation (assuming they don't crash, or leak
memory!). You have the freedom to keep database connections open between requests
or cache ready-parsed responses, for example. It becomes realistic to store
expensive state in your web applications, safely under the assumption that
your program starts up and shuts down infrequently and done preemptively by
your favourite web server. Processing of a client request can even be continued
in the case of the client crashing - the response
can then be stored and given to them when they return - saving precious CPU
cycles.
The downside is added complexity: managing multiple requests and having to keep a tight reign on memory/resource consumption.
You might think dealing with request queues could be a handful but, fortunately, management of the queue (or queues, if you'd prefer) can be largely isolated from everything else. Accepting requests and handling them are your two key responsibilities. That means that after you have set up a 'server' (ie. something that gathers requests), requests can be handled in an essentially protocol-agnostic way.
Now on to some demonstrations...